

現代のデジタル社会において、データベースはあらゆるアプリケーションの心臓部として機能しています。ユーザーがスマートフォンを数回タップしてレストランを予約したり、ECサイトで商品を検索したりする裏側では、膨大な数の「クエリ(命令)」がデータベースに対して発行されています。しかし、このクエリの実行に時間がかかり、ユーザーを待たせてしまう現象が「スロークエリ」です。スロークエリは単なる技術的な遅延に留まらず、企業の収益性、ブランドの信頼性、そして開発チームの生産性に多大な悪影響を及ぼします 1。
本レポートでは、スロークエリの基礎知識から、SQLパフォーマンス向上のための歴史的な最適化理論、そして2025年現在、スロークエリと生成AIがどのように関わっているのかまで、海外の最新文献や技術事例を基に網羅的に解説します。非専門家の方にも理解しやすいよう、レストランの運営に例えた一般的な解説を織り交ぜつつ、データベース管理者(DBA)やエンジニアにとっても実用的な洞察を提供します。


スロークエリとは何か:概念とビジネスへの影響
データベースにおける「クエリ」とは、データの検索、追加、更新、削除を行うための命令セットを指します。スロークエリとは、この命令の処理が、あらかじめ設定された閾値(しきい値)を超えて時間を要してしまった状態のことです 3。
レストランに例えるデータベースとクエリの仕組み
専門用語が多くなりがちなデータベースの世界を理解するために、レストランの運営を例に考えてみましょう 4。
- お客様(ユーザー/アプリケーション): 情報が欲しい、あるいはデータを更新したいと願う存在です。
- ウェイター(API/クエリ): お客様の注文を受け取り、厨房に伝える役割を担います。
- 厨房(サーバー/データベース): 膨大な食材(データ)が保管されており、注文に合わせて調理(データ処理)を行う場所です。
- メニュー(APIドキュメント/スキーマ): お客様が何を注文できるか、どのような形式で結果が返ってくるかを定義しています。
スロークエリが発生している状態とは、注文した料理がなかなかテーブルに届かない状態を指します。その原因はさまざまです。厨房が非常に混雑している(リソース不足)、シェフが食材の場所を知らずに倉庫の端から端まで探し回っている(インデックスの欠如)、あるいは注文内容が複雑すぎて調理に物理的な時間がかかる(非効率なSQL設計)といった状況が考えられます 2。
スロークエリがビジネスに与える「見えないコスト」
スロークエリは、単に「画面の表示が遅い」という不満以上のダメージを企業に与えます。海外の調査によれば、モバイルページの読み込みがわずか0.1秒遅れるだけで、成約率(コンバージョン率)が最大10%低下するという報告があります 2。
| 影響カテゴリ | 具体的なリスク | 経済的・組織的影響 |
| ユーザー体験 | ページ読み込み時間の増大、アプリのフリーズ 2 | 顧客満足度の低下、競合他社への流出 2 |
| 収益性 | カート放棄率の上昇、広告クリック後の離脱 7 | 直接的な売上の減少、マーケティング投資の無駄 7 |
| 信頼性 | 金融機関の残高反映遅延、在庫情報の不一致 2 | ブランドイメージの棄損、顧客の不信感 2 |
| インフラコスト | CPU使用率のスパイク、メモリ消費の増大 7 | 過剰なサーバー課金、クラウド利用料の増大 7 |
| 生産性 | エンジニアによる「火消し」作業の頻発 7 | 新機能開発の停滞、開発チームの疲弊 7 |
特に金融機関などの厳格な環境では、クエリの遅延はデータの一貫性に影響を及ぼし、重大なトラブルに発展しかねません 2。スロークエリは、企業の成長を阻害する「静かなる毒」であると言えます。
技術的側面:スロークエリの特定と監視
データベースシステムは、一定時間以上かかったクエリを「スロークエリログ」として記録する機能を備えています。これを分析することが、最適化の第一歩となります 2。
ログに記録される主要な指標
スロークエリログには、単なる実行時間だけでなく、診断に不可欠な複数の統計情報が含まれています 3。
- Query_time(実行時間): 処理の開始から終了までにかかった総時間です。
- Lock_time(ロック待ち時間): 他の処理が同じデータを使用しており、順番待ちをしていた時間です 10。
- Rows_sent(送信行数): 最終的にユーザーに返されたデータの件数です。
- Rows_examined(精査行数): 結果を得るために、データベースが実際に読み取る必要があったデータの総件数です 3。
ここで特に注目すべきは Rows_examined(精査行数)と Rows_sent(送信行数)の比率です。例えば、わずか15件のデータを表示するために、データベースが120万行ものデータを読み取っている場合、そのクエリは極めて非効率であり、改善の余地が大きいことを示唆しています 8。
データベース別:ログ設定と管理フラグ
主要なデータベースシステムにおける監視設定を比較します。現代のクラウド環境(AWS RDSやGoogle Cloud SQLなど)では、これらの設定をコンソールやCLIから容易に変更できます 10。
| 設定項目 (MySQL/MariaDB) | 説明 | 推奨される考え方 |
| slow_query_log | 機能を有効にするか否か | 常時有効化が推奨される 8 |
| long_query_time | 記録する閾値(秒) | デフォルトの10秒は長すぎる。1秒以下が一般的 3 |
| log_output | 出力先(FILE, TABLE) | クラウド監視連携にはFILEが好まれる 10 |
| log_queries_not_using_indexes | 索引なしクエリを記録 | 実行時間が短くても「時限爆弾」となるため有効化すべき 10 |
| log_slow_admin_statements | 管理命令(ALTERなど)を記録 | スキーマ変更による影響を把握するために有用 10 |
PostgreSQLにおいても同様の概念が存在し、pg_stat_statements 拡張機能を用いることで、クエリごとの累積実行時間や平均時間を詳細に追跡することが可能です 7。最新のPostgreSQL 15や17では、ブロックの読み書き時間の分離がより細分化されており、I/O性能のボトルネックを特定しやすくなっています 13。
データベース最適化の歴史と理論的背景
スロークエリの解決策を深く理解するためには、データベースがどのように進化し、どのようにクエリを最適化する機能を獲得してきたかを知る必要があります。
1979年、セリンジャーの衝撃
データベース最適化の歴史において、最も重要なエポックメイキングは、1979年に発表されたパトリシア・セリンジャー(Patricia Selinger)らによる論文『リレーショナルデータベース管理システムにおけるアクセスパス選択(Access Path Selection in a Relational Database Management System)』です 14。
この論文が登場する前、データベースへの命令は「命令型(Imperative)」でした。つまり、開発者が「まずAというファイルを読み込み、Bというインデックスを使って照合しろ」といった手順を事細かに指示しなければなりませんでした。しかし、SQLのような「宣言型(Declarative)」言語の普及により、ユーザーは「何が欲しいか(What)」だけを記述し、その「手順(How)」はデータベース側の「オプティマイザ」が決定するようになりました 15。
セリンジャーらは、以下の3つの柱からなる「コストベース最適化(CBO)」の基礎を築きました。
- 統計情報のカタログ化: テーブルの行数、ページ数、インデックスの分布などのメタデータを保持します 14。
- コスト算出モデル: CPU処理能力やI/O(ディスク読み込み)回数を基に、各実行手順の「コスト」を数式で算出します 15。
- ジョインの順序決定: 複数のテーブルを結合する際、動的計画法を用いて最も効率的な結合順序を導き出します 14。
この時、提案された基本的なコスト計算式は、現代の複雑なオプティマイザの原点となっています。
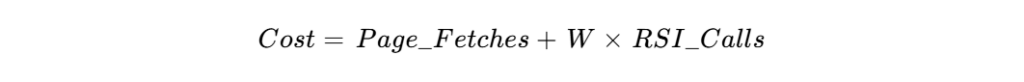
スロークエリの原因と解決策
ここで、Page_Fetchesはディスクアクセス回数、RSII_Callsは処理されるレコード数を表し、Wはその重み係数です 15。
アムダールの法則とクエリ最適化の優先順位
スロークエリ対策において、どのクエリから手を付けるべきかを判断する際、コンピュータ科学における「アムダールの法則(Amdahl’s Law)」が有用です 13。これは、システム全体のうち一部を高速化した場合、全体の速度がどれだけ向上するかを予測する理論です。
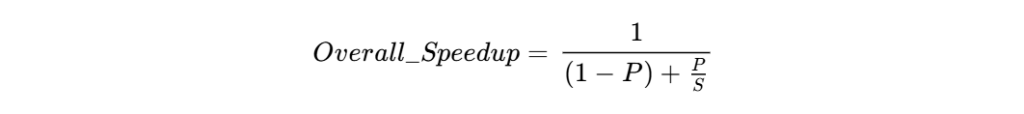
- P : 最適化された部分の割合(全クエリ時間に占めるそのクエリの比率)
- S : その部分の高速化倍率
この法則が示唆するのは、「実行に5秒かかるが1日に1回しか走らないクエリ」を2.5秒に短縮するよりも、「実行に200ミリ秒かかるが1分間に1万回走るクエリ」を100ミリ秒に短縮する方が、システム全体の負荷軽減に大きく寄与するということです 10。そのため、DBAは「平均実行時間」だけでなく、「総実行時間(累積実行時間)」に着目して最適化の優先順位を決定します 7。
SQLパフォーマンス低下を招くスロークエリの主な原因と4つの改善手法
SQLパフォーマンス問題の約9割は全体の約1割の「悪いクエリ」に起因しています 7。
1. インデックス(索引)の設計ミス
最も頻繁に見られる原因は、適切なインデックスが設定されていないことです。インデックスがない場合、データベースは数千万行のデータから特定の1行を探すために、最初から最後まで全てのデータを読み込みます(フルテーブルスキャン) 1。
- 原因: WHERE句やJOINの結合条件に使用されているカラムにインデックスがない 7。
- 改善: EXPLAIN コマンドで実行計画を確認し、type=ALL や full scan と表示されている箇所にインデックスを追加します 1。
- 実例: 1,000万行のテーブルに対するクエリが、適切なインデックスを追加しただけで実行時間が8.5秒から0.003秒へ劇的に改善した事例があります 7。
2. 相関サブクエリとN+1問題
アプリケーション側のロジックに起因する問題も少なくありません。特にORM(オブジェクト関係マッピング)を使用している際、1つのクエリで済むところを、ループ内で何度も個別のクエリを発行してしまう「N+1問題」が発生しやすくなります 7。
- 原因: 注文一覧を取得した後、各注文の配送状況を1つずつ個別のクエリで取得する 7。
- 改善: JOIN(結合)を使用して1つのクエリで全ての情報を取得するか、アプリケーション側で一括読み込み(Eager Loading)を設定します 7。
- 実例: ループ内でのクエリ発行を JOIN に書き換えることで、処理時間が70%削減されたケースが報告されています 8。
3. SELECT * の不適切な使用
必要のないカラムまで全て取得する SELECT * は、データベースのI/O、ネットワーク帯域、メモリを浪費します 2。
- 原因: ユーザーのIDと名前だけが必要なのに、巨大なJSONデータや画像バイナリが含まれる全カラムを取得している 7。
- 改善: 必要なカラム名だけを明示的に指定します。これにより、インデックスに含まれるデータのみでクエリが完結する「カバリングインデックス(Covering Index)」が効くようになり、テーブル本体へのアクセスが不要になるメリットもあります 7。
4. 統計情報の劣化と計画の迷走
データベースのオプティマイザは統計情報を基に判断を下しますが、大量のデータ更新後に統計情報が更新されていないと、誤った計画(スキャン方法の選択ミスなど)を選択してしまいます 1。
- 原因: テーブル内のデータ分布が大きく変わったが、統計情報が古いまま 1。
- 改善: ANALYZE TABLE(MySQL/MariaDB/PostgreSQL)を定期的に実行し、統計情報を最新に保ちます。多くのマネージドサービスでは自動化されていますが、急激なデータ増殖時には手動実行が必要な場合もあります 7。
| 最適化手法 | 効果が期待できるシーン | 注意点 |
| カバリングインデックス | 特定のクエリを極限まで高速化したい時 7 | インデックスサイズが増大し、書き込みが若干遅くなる 7 |
| パーティショニング | ログデータや時系列データを扱う時 7 | パーティションキーの設計を誤ると逆に遅くなる 7 |
| ウィンドウ関数 | ランキングや移動平均の算出 7 | 自己結合(Self-join)より15倍高速になる場合がある 7 |
| マテリアライズドビュー | 複雑な集計結果を事前計算しておきたい時 | データの鮮度管理(リフレッシュ)が必要 |
高度なアーキテクチャによる解決:Uberの事例研究
大規模なトラフィックを抱えるグローバル企業では、SQLの最適化だけでは限界に達することがあります。ライドシェア大手のUberは、スロークエリとコストの問題を革新的なアーキテクチャで解決しています 18。
キャッシュ戦略によるDB負荷の劇的低減
Uberは、MySQLをベースにした分散データベース「Docstore」において、秒間4,000万回から1億5,000万回という膨大なリード(読み取り)リクエストを処理しています 18。
- 課題: 600万リード/秒の負荷を処理するために、当初は6万個のCPUコアが必要と見積もられました。これはコスト面で非現実的でした 18。
- 解決策「CacheFront」: データベースのクエリエンジン層にRedisキャッシュを統合しました。クエリエンジンがリクエストを受け取ると、まずRedisを確認し、キャッシュミスした場合のみMySQLにアクセスする「透過的キャッシュ」を構築しました 18。
- データ一貫性の維持: キャッシュの最大の問題は、本体のデータが更新された時にキャッシュが古くなる(不整合)ことです。UberはCDC(Change Data Capture)エンジンを用いてMySQLのバイナリログをリアルタイムで監視し、更新があった瞬間にRedisの該当エントリを無効化する仕組みを作りました 18。
- 成果:
- リードレイテンシを75%削減(P75レイテンシ基準) 18。
- 計算リソースを6万コアから3,000コアへ削減(95%のコストカット) 18。
- キャッシュヒット率は驚異の99.9%を達成 18。
Uberのエンジニアリングチームは、単にデータベースを大きく(垂直スケール)するのではなく、「そもそもデータベースのディスクを叩かなくて済む仕組み」を作ることでスロークエリを根絶したのです。
スロークエリと生成AI:2025年の最新トレンドと新たなパフォーマンスリスク
2024年から2025年にかけて、データベース界隈で最も熱い議論を呼んでいるのがスロークエリと生成AI(Generative AI)の関わりです。AIはスロークエリの解決を助ける一方で、新たなパフォーマンスリスクも生み出しています。

生成AIがもたらす新たな「スロークエリ」リスク
企業内でLLM(大規模言語モデル)を業務活用する際、自然言語からSQLを自動生成してデータベースに問い合わせる「Text-to-SQL」の試みが進んでいます。しかし、ここには技術的な落とし穴が潜んでいます。
- 制御不能なクエリの爆発: LLMが生成するSQLは、時に人間には想像もつかないほど非効率なJOINや巨大なスキャンを含むことがあります。これをエージェントが自律的に本番環境で実行すると、一瞬でシステムのリソースを食いつぶすリスクがあります 19。
- ハルシネーション(幻覚)と性能: AIが「もっともらしいが間違った」クエリを作成することがあります。特定の研究では、LLMによる回答やクエリ生成の20%〜27%に何らかの虚偽(ハルシネーション)が含まれているとされています 20。
- セマンティック層の欠如: 企業のデータベーススキーマは複雑です。AIがビジネスルール(例:『売上』の計算式にはキャンセル分を含まない等)を理解せずにクエリを投げると、論理的に誤った結果が返ってくるだけでなく、意図しない全件検索を誘発します 19。
ベクトル検索とRAGのレイテンシ課題
LLMに専門知識を与える手法として「RAG(検索拡張生成)」が標準的になりましたが、ここでは「ベクトル検索」特有のスロークエリ問題が発生します 21。
ベクトル検索は、テキストの意味を数値(ベクトル)化し、その「距離」を計算することで類似性を判断します。しかし、数億次元のデータを厳密に比較すると、従来のB-Tree検索とは比較にならないほど時間がかかります 23。
- 検索のボトルネック: RAGパイプライン全体の中で、ベクトル検索が「最初の1文字を出すまでの時間(TTFT: Time-to-First-Token)」の最大85.8%を占める場合があることが報告されています 23。
- 近似検索(ANN)のジレンマ: 速度を上げるために「近似最近傍探索」を用いますが、精度(Recall)を求めすぎると検索範囲が広がり、急激にレイテンシが悪化します 23。
- GPU vs CPUのリソース争奪: RAGシステムでは、ベクトル検索とLLM推論を同じGPUで動かすことがありますが、検索がメモリとI/Oを占有するとLLMの推論が遅れるという、新たなリソース競合問題(VectorLiteRAGなどの研究対象)が起きています 26。
| データベース種別 | 検索の考え方 | パフォーマンスの主な制約 |
| リレーショナル (SQL) | 厳密な一致、範囲指定 24 | I/O回数、ロック、結合の複雑さ 10 |
| ベクトルデータベース | 意味の近さ(コサイン類似度等) 27 | ベクトル演算の計算量、メモリ帯域 26 |
AIによる自動最適化の恩恵
リスクの一方で、AIは強力な「自律的DBA」としての側面も持っています。
- インデックス・アドバイザー: Google Cloud SQL Insightsなどは、AIが実際の負荷パターンを学習し、「このインデックスを追加すればコストがこれだけ下がる」という推奨を自動で行います 28。
- 自動クエリリライト: AI2SQLやEverSQLのようなツールは、非効率なSQLを解析し、セマンティック(意味)を維持したまま高速な形式へ自動的に書き換えます。ある事例では、複雑なクエリの効率が14,000%向上したという驚異的な結果も出ています 30。
- 予測的なスケーリング: AWS DevOps Guru for RDSなどは、過去のデータから負荷のスパイクを予測し、問題が発生する前にリソースを調整するよう警告を発します 30。
スロークエリ対策:実践的な改善ステップ
これまでの情報を踏まえ、現場でスロークエリをどのように解決すべきかのロードマップをまとめます。

ステップ1:現状の把握(可視化)
「計測できないものは改善できない」という格言通り、まずはスロークエリログを有効化し、どのクエリがどれだけリソースを消費しているかを可視化します 8。
- long_query_time をまずは1秒、最終的には200〜500ミリ秒に設定してデータを収集します 10。
- 累積実行時間の長い上位5つのクエリを「最適化対象」として選別します 10。
ステップ2:原因の特定(EXPLAIN)
対象クエリに対して EXPLAIN(またはPostgreSQLの EXPLAIN ANALYZE)を実行し、実行計画を確認します。
- type: ALL(フルテーブルスキャン)はないか? 7
- Using temporary(一時テーブル作成)や Using filesort(ファイルソート)が発生していないか? 7
- 結合順序は最適か?(駆動表が最も絞り込まれるようになっているか) 14
ステップ3:対策の実行(インデックス・リライト)
原因に合わせて適切な処置を施します。
- インデックス追加: フィルタリングやソートに使われるカラムに索引を貼ります 1。
- クエリのリライト: サブクエリをJOINへ、あるいはウィンドウ関数へ書き換えます 7。
- スキーマ変更: 必要に応じてデータを非正規化し、複雑な結合を回避します。
- キャッシング: Uberの例のように、不変性の高いデータについてはキャッシュ層(Redis等)へ逃がします 18。
ステップ4:効果の検証と継続的な監視
対策実施後、再度スロークエリログを確認し、実行時間が期待通りに短縮されたかを検証します 7。
- データ量が増えてもパフォーマンスが維持されるか、本番相当のデータ規模で再テストを行います。
- 統計情報の更新を自動化し、時間の経過による性能劣化を防ぎます 7。
結論とこれからのデータベース管理
スロークエリとの戦いは、データベースが存在する限り続く終わりのないプロセスです。しかし、1979年のセリンジャーらによる先駆的な研究から、2025年の最新AI技術に至るまで、私たちはより高度な武器を手に入れてきました。
スロークエリ対策の本質は、単に「SQLを短く書く」ことではなく、「データベースがデータにアクセスするまでの物理的な抵抗を最小限に抑える」ことにあります。インデックスの設計、アプリケーションの挙動、そしてインフラ構成までを鳥瞰的に捉えることが、現代のエンジニアや管理者には求められています。
また、生成AI時代の到来により、データベース管理は「人間がクエリを書く」時代から「AIがクエリを書き、人間がそのガバナンスを管理する」時代へとシフトしつつあります。AIが引き起こす予測不能な負荷を制御し、一方でAIの力を借りて自律的なチューニングを行う——このバランス感覚こそが、これからのビジネスのスピードと品質を左右する鍵となるでしょう。
最後に、スロークエリ対策を技術的な「メンテナンス作業」としてではなく、ユーザー体験を高め、ビジネス価値を最大化するための「投資」として捉えることが、企業の競争力を高める第一歩となります。
引用文献
- Slow SQL Queries: How to Diagnose and Optimize Them – SQream, 4月 15, 2026にアクセス、 https://sqream.com/blog/slow-sql-queries/
- How Slow Queries Hurt Your Business (and How to Fix Them) | Redis, 4月 15, 2026にアクセス、 https://redis.io/blog/how-slow-queries-hurt-your-business/
- Slow Query Analysis – Tencent Cloud, 4月 15, 2026にアクセス、 https://www.tencentcloud.com/ind/document/product/237/8715
- Restaurant Analogy – by Sashanka Rathnayaka – Medium, 4月 15, 2026にアクセス、 https://medium.com/@chamudi_sashanka/restaurant-analogy-b8655319a568
- APIs Explained Simply: Talking to Servers like ordering at a Restaurant – DEV Community, 4月 15, 2026にアクセス、 https://dev.to/mehta0007/apis-explained-simply-talking-to-servers-like-ordering-at-a-restaurant-20e9
- Understanding Redis & BullMQ Using a Restaurant Analogy | by Zohaib Saeed – Medium, 4月 15, 2026にアクセス、 https://medium.com/@zohaibsaeed/understanding-redis-bullmq-using-a-restaurant-analogy-8eed9b64dc27
- Database Query Optimization: The Complete DBA Guide to …, 4月 15, 2026にアクセス、 https://medium.com/@jholt1055/database-query-optimization-the-complete-dba-guide-to-identifying-and-fixing-slow-queries-in-2025-80cf25c1c7bb
- How We Caught Slow Queries Early and Built a Database That Scales Without Pain | by Karan Gupta – Medium, 4月 15, 2026にアクセス、 https://medium.com/@gkaran2580/how-we-caught-slow-queries-early-and-built-a-database-that-scales-without-pain-9e154bc84f6f
- How DoorDash slashed web developer build times, 4月 15, 2026にアクセス、 https://careersatdoordash.com/blog/how-doordash-slashed-web-developer-build-times/
- How to Enable and Analyze Slow Query Logs in Cloud SQL MySQL, 4月 15, 2026にアクセス、 https://oneuptime.com/blog/post/2026-02-17-how-to-enable-and-analyze-slow-query-logs-in-cloud-sql-mysql/view
- Use query insights to improve query performance | Cloud SQL for SQL Server, 4月 15, 2026にアクセス、 https://docs.cloud.google.com/sql/docs/sqlserver/using-query-insights
- Slow Query Log Overview | Server | MariaDB Documentation, 4月 15, 2026にアクセス、 https://mariadb.com/docs/server/server-management/server-monitoring-logs/slow-query-log/slow-query-log-overview
- What counts as a “slow database query”? It’s surprisingly hard to say – DEV Community, 4月 15, 2026にアクセス、 https://dev.to/jssmith/what-counts-as-a-slow-database-query-its-surprisingly-hard-to-say-2bgi
- Access Path Selection in a Relational Database Management System, 4月 15, 2026にアクセス、 https://hpi.de/rabl/teaching/winter-term-2019-20/foundations-of-database-systems/access-path-selection-in-a-relational-database-management-system.html
- Access Path Selection in a Relational Database Management System | by Heather Arthur, 4月 15, 2026にアクセス、 https://heathermoor.medium.com/access-path-selection-in-a-relational-database-management-system-41f5735bb6d1
- Access path selection in a relational database management system selinger1979access. – Data Visualization Courses, 4月 15, 2026にアクセス、 http://datavis.cs.columbia.edu/files/prospectus/prospectus.pdf
- Paper Review: Access Path Selection in a Relational Database Management System, 4月 15, 2026にアクセス、 https://sookocheff.com/post/databases/access-path-selection-in-a-rdbms/
- How Uber Scaled from 40M to 150M Database Reads/Second …, 4月 15, 2026にアクセス、 https://balevdev.medium.com/how-uber-scaled-from-40m-to-150m-database-reads-second-without-adding-more-databases-28b07688d230
- What Is Causing AI Hallucinations With Analytics? | insightsoftware, 4月 15, 2026にアクセス、 https://insightsoftware.com/blog/what-is-causing-ai-hallucinations-with-analytics/
- LLM Hallucination Statistics 2026: Hidden Risks Now – SQ Magazine, 4月 15, 2026にアクセス、 https://sqmagazine.co.uk/llm-hallucination-statistics/
- Why is the efficiency of the vector store important in a RAG system, and how does it affect the overall user experience (consider both latency and throughput)? – Milvus, 4月 15, 2026にアクセス、 https://milvus.io/ai-quick-reference/why-is-the-efficiency-of-the-vector-store-important-in-a-rag-system-and-how-does-it-affect-the-overall-user-experience-consider-both-latency-and-throughput
- Vector search benchmarking: Setting up embeddings, insertion, and retrieval with PostgreSQL® – Instaclustr, 4月 15, 2026にアクセス、 https://www.instaclustr.com/blog/vector-search-benchmarking-setting-up-embeddings-insertion-and-retrieval-with-postgresql/
- An Adaptive Vector Index Partitioning Scheme for Low-Latency RAG Pipeline – arXiv, 4月 15, 2026にアクセス、 https://arxiv.org/html/2504.08930v1
- Vector database vs. Relational database: 7 key differences – NetApp Instaclustr, 4月 15, 2026にアクセス、 https://www.instaclustr.com/education/vector-database/vector-database-vs-relational-database-7-key-differences/
- Best Vector Databases in 2026: A Complete Comparison Guide – Firecrawl, 4月 15, 2026にアクセス、 https://www.firecrawl.dev/blog/best-vector-databases
- VectorLiteRAG: Latency-Aware and Fine-Grained Resource Partitioning for Efficient RAG, 4月 15, 2026にアクセス、 https://arxiv.org/html/2504.08930v2
- Vector Databases vs. Traditional Relational Databases: A Comprehensive Comparison (using Bob :p), 4月 15, 2026にアクセス、 https://alain-airom.medium.com/vector-databases-vs-traditional-relational-databases-a-comprehensive-comparison-using-bob-p-cb91f39bd49d
- Top Google Cloud SQL Cost & Performance Optimization Tools for 2025 – Sedai, 4月 15, 2026にアクセス、 https://sedai.io/blog/google-cloud-sql-optimization-tools-for-2025
- Use query insights to improve query performance | Cloud SQL for MySQL, 4月 15, 2026にアクセス、 https://docs.cloud.google.com/sql/docs/mysql/using-query-insights
- Query Optimization with AI‑Powered Assistants – Refonte Learning, 4月 15, 2026にアクセス、 https://www.refontelearning.com/blog/query-optimization-with-ai-powered-assistants
- How AI is Transforming SQL Query Optimization in 2025 – AI2sql, 4月 15, 2026にアクセス、 https://ai2sql.io/how-ai-is-transforming-sql-query-optimization-2025
- 2025 SEO trends and predictions: Navigating the future of organic search – Envisionit, 4月 15, 2026にアクセス、 https://envisionitagency.com/blog/seo-trends-and-predictions-for-2025/
- 【2025年版】SEO対策の最新トレンドと実践法 | GUARDIAN Marketing BLOG, 4月 15, 2026にアクセス、 https://guardian.jpn.com/marketing_blog/20250627-seo_trend/
- 【2025年版】SEO対策を初心者向けに完全ガイド!即効性のある実践事例も解説 | Digital Creative Blog Whale | 博報堂アイ・スタジオ, 4月 15, 2026にアクセス、 https://www.i-studio.co.jp/whale/seo-howto/
- SEOの検索順位が上がらない14の理由!2025年に重要なのは「 」だった – メディアリーチ, 4月 15, 2026にアクセス、 https://mediareach.co.jp/blog/search-ranking-not-improving
- 2025年のSEOトレンドを専門家23人が予測: AI、多角化、グーグル次の一手(前編) | Moz, 4月 15, 2026にアクセス、 https://webtan.impress.co.jp/e/2025/01/27/48473
- 2025年版:Googleが重視する新SEOシグナル完全ガイド – Marketing Hacks. – GROP, 4月 15, 2026にアクセス、 https://www.grop.co.jp/marketinghacks/blog_25033102/
- SEO Strategies for 2025: Key Trends and Best Practices – DigitalScouts, 4月 15, 2026にアクセス、 https://digitalscouts.co/blog/seo-strategies-for-2025-key-trends-and-best-practices
- SEO in 2025: 10 Biggest Trends with Actionable Examples – OceanWP, 4月 15, 2026にアクセス、 https://oceanwp.org/blog/seo-biggest-trends/
- Understanding SEO in 2025 | Info Cubic Japan Blog, 4月 15, 2026にアクセス、 https://www.icrossborderjapan.com/en/blog/sem/understanding-seo-in-2025/












